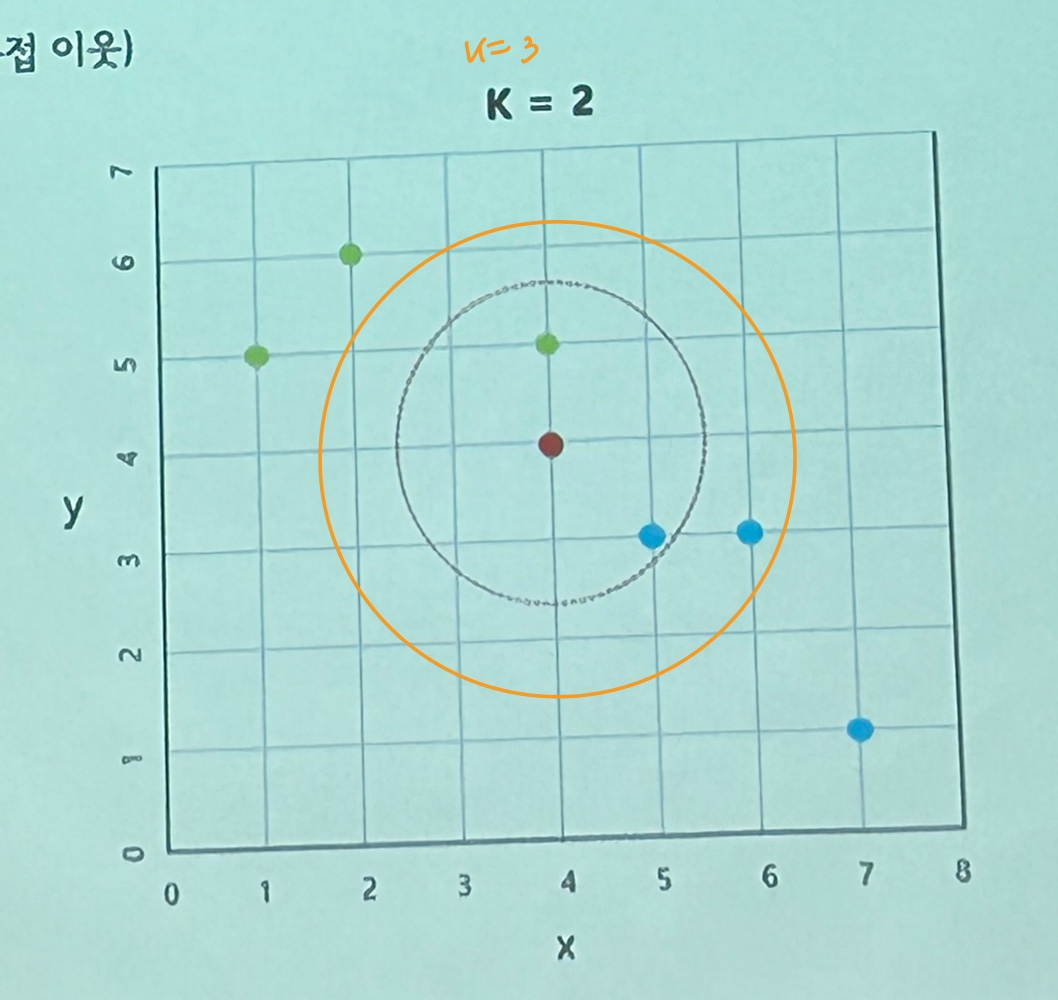
K-Nearest Neighbors(K-최근접 이웃)
새로운 데이터를 입력받으면 기존 클러스터에서 모든 데이터와 유클리드 기반 거리를 측정 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘이다. 새 데이터가 어떤 카테고리에 속하는지 알기 위해서는 가까이에 있는 k개의 정답데이터를 보고 추론한다.
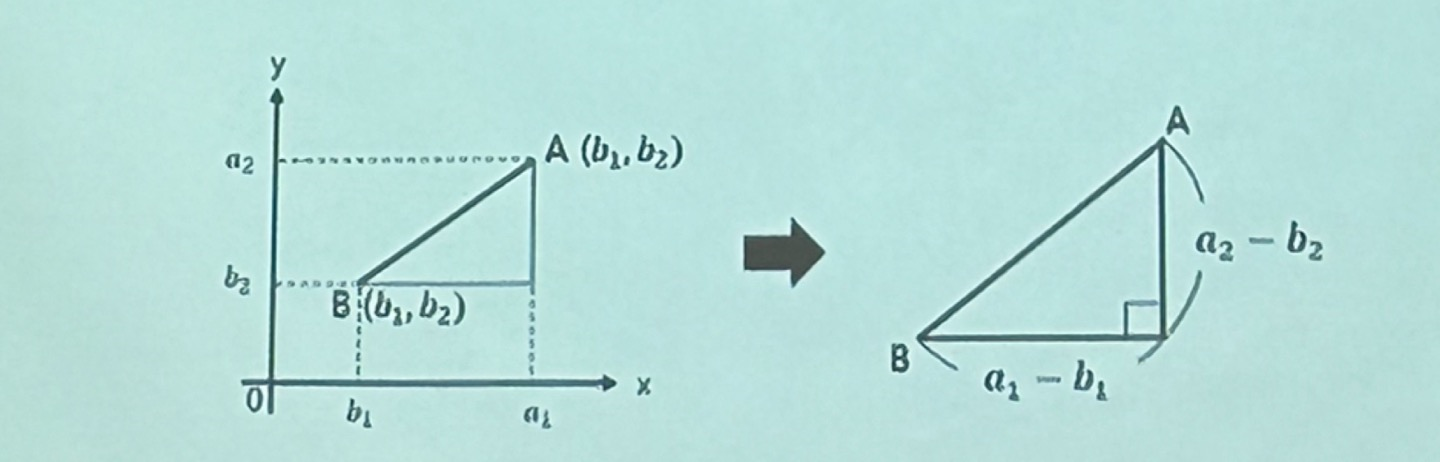
유클리드거리
2차원 평면에 서로 다른 두 점 A(a1,a2) 와 B(b1,b2) 가 있을때, 둘 사이의 거리를 구하는 방법
A와 B의 대각선 거리를 구하는 식은 √(a1-b1)^2 + (a2-b2)^2 으로 표현된다.
여기서 k는 홀수로 잡아야 동등한 값이 나오지 않게 하기 위해 홀수로 지정하는 것이 좋다.
[실습] 붓꽃 품종 분류
패키지 로딩
K-NN은 neighbors 의 KNeighborsClassifier 를 사용한다.
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
데이터 로딩 및 분할
x,y = load_iris(return_X_y = True)
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size= 0.3,
random_state= 10, stratify= y)
모델 생성 및 학습
model = KNeighborsClassifier(n_neighbors = 3 ) # n_neighbors : k의 값
model.fit(x_train,y_train)
예측 및 평가
y_hat = model.predict(x_test)
con_mat = confusion_matrix(y_test,y_hat)
print(con_mat)[[15 0 0]
[ 0 15 0]
[ 0 0 15]]정확히 분류한 것을 알 수 있다.
최적의 K 찾기
k는 적절한 분류의 값을 찾는 것이기 때문에 임의적으로 값을 넣어야한다.
하지만, 그 넣는 값 중에 최적의 값이 무엇인지는 찾을 수 있다.
import numpy as np
k = 10
acc_score = np.zeros(k)
for k in range(1,k+1):
model = KNeighborsClassifier(n_neighbors=k).fit(x_train,y_train)
y_hat = model.predict(x_test)
acc = accuracy_score(y_test,y_hat)
acc_score[k-1] = acc
max_index = np.argmax(acc_score)
print(acc_score)
print(f'최적의 k는 {max_index+1} 이며 정확도는 {acc_score[max_index]:.3f} 이다.')최적의 k는 1 이며 정확도는 1.000 이다.
[1. 1. 1. 0.97777778 1. 1.
1. 1. 1. 0.97777778]np.argmax()를 이용하여 최적의 k의 인덱스의 위치를 찾은 것이므로 출력때에는 인덱스 자리에 +1을 한다. (k를 1~10 까지 넣었으므로) 하지만 이 데이터에서는 acc_score를 보면 대부분 높은 확률의 정확도를 가지고 있기 때문에 큰 영향이 없다는 것을 알 수 있다.
[실습] MNIST 손글씨 분류
MNIST(Modified National Institute of Standard and Technology) : 손으로 쓴 숫자들로 이루어진 데이터베이스이다.
데이터로딩
위에 패키지에 필요한 패키지만 더하여 사용하였다.
fetch_openml('mnist_784', version =1, parser = 'pandas') 옵션을 주어 판다스의 데이터프레임으로 읽어올 수 있게 한다.
from sklearn.datasets import fetch_openml # 데이터 제공
mnist = fetch_openml('mnist_784', version =1, parser = 'pandas') # 번치 객체 형태
print(type(mnist))
데이터 모양 확인
전체 70,000 개의 이미지와 784 개의 특성값 (28x28 픽셀 이미지)을 가지고 있다.
이처럼 데이터셋에서 읽어오는 친구들은 독립변수와 종속변수를 .data / .target 으로 읽는 것이 가능하다.
x = mnist.data
y = mnist.target
print(x.shape, y.shape)
print(type(x))
display(x.head())(70000, 784) (70000,)
숫자 데이터 이미지화
import matplotlib.pyplot as plt
img_data = x.iloc[0].values.reshape(28,28) # 2차원 배열
plt.imshow(img_data, cmap='binary')
plt.axis('off')
plt.show()0번째 행의 값을 가져와 2차원 배열로 만들어준 후 imshow()를 통해 이미지를 보여준다.

학습데이터, 평가데이터 분리
(특이점) MNIST 데이터셋은 이미 학습데이터(앞쪽 6만개), 평가데이터(뒤쪽 만개)로 나뉘어져 있기 때문에 train_test_split() 함수를 이용해 랜덤으로 값을 나누는 것이 아닌 나뉘어진 데이터를 따로 지정하여야 한다.
x_train, x_test, y_train, y_test = x[:60000], x[60000:],y[:60000], y[60000:]
모델 생성및 학습
' n_neighbors ' : k 값을 설정하는 옵션이다.
knn = KNeighborsClassifier(n_neighbors= 5)
knn.fit(x_train,y_train)
예측 및 평가
y_hat = knn.predict(x_test)
print(f'정확도: {accuracy_score(y_test,y_hat):.3f}')정확도: 0.969
from sklearn.metrics import roc_auc_score
pred_proba = knn.predict_proba(x_test)
print(f'AUC : {roc_auc_score(y_test,pred_proba, multi_class = "ovr"):.3f}') # 1에 근접한 값AUC : 0.995높은 비율의 정확도가 나오는 것을 알 수 있다.
예측값 확인
2차원 배열로 넣었으나 예측할때에는 1차원으로 차원을 축소시켜준다.
knn.predict(img_data.reshape(1,-1))array(['5'], dtype=object)예측값이 맞음을 알 수 있다.
'국비 교육 > 머신러닝, 딥러닝' 카테고리의 다른 글
| [머신러닝] 분류분석 : 앙상블 러닝 - Voting, Boosting 실습문제 (0) | 2023.11.23 |
|---|---|
| [머신러닝] 분류분석 : 의사 결정 트리, 앙상블 러닝 - Bagging (0) | 2023.11.22 |
| [머신러닝] 분류분석 : 나이브 베이즈 분류 (0) | 2023.11.22 |
| [머신러닝] 분류분석 : [다지분류]로지스틱 회귀분석 (0) | 2023.11.21 |


