배열 생성 -1
> array()를 이용한 생성 :: 대표적
파이썬의 list나 tuple을 이용해서 numpy의 ndarray를 생성한다. 다차원 배열의 모든 원소는 동일한 데이터 타입을 가져야 한다.
- 정수형
int64, int32(기본타입), int16, int8, uint64 형이 있다. 64,32.. = 크기
int64 : -2^63 ~ 2^63 -1 까지의 정수 표현
64개의 비트: 1(부호비트)+63비트(값 저장 비트)
-1: 맨 앞 부호 비트가 0이고 63 개가 1로 채워졌을때 취할 수 있는 범위
uint64: 0 ~ 2^64-1 까지의 정수 표현 (부호비트가 없기때문에 64개를 다 사용한다.)
- 실수형
실수형의 default type 은 'float64'
# 데이터 타입 확인
intArray = np.array([[1,2],[3,4]])
print(intArray.dtype)
# dtype 을 지정하면 형변환이 가능하다.
uintArray = np.array([[1,2],[3,4]], dtype = 'uint')
print(uintArray.dtype)
floatArray = np.array([[1.1,2.2],[3.3,4.4]])
print(floatArray.dtype)> 형변환
데이터가 정수로 입력 되더라도 dtype의 값으로 실수형을 명시한다면 실수형으로 자동 형변환이 이뤄진다.
a = np.array(['1', '2', 3, 4], dtype = np.float64)
print(a) # [1. 2. 3. 4.]
print(type(a[0])) # <class 'numpy.float64'>> copy 옵션 사용
a = np.array([1,2,3,4])
b = np.array(a, copy = False)
print(a, id(a))
print(b, id(b))
# [1 2 3 4] 2079173639984
# [1 2 3 4] 2079173639984
# 두 변수가 주소까지 동일한 것을 알 수 있다.copy = False : 새로운 np.array() 생성이 아닌 동일한 참조값을 받는 것이다. ' b = a ' 와 동일한 표현
> arange() 를 이용한 생성
일련의 숫자를 만들기 위해 arange() 함수를 사용한다.
a = np.arange(1,10)
print(a) # [1 2 3 4 5 6 7 8 9]
b = np.arange(10,30,5)
print(b) # [10 15 20 25]
c = np.arange(0,2,0.3)
print(c) # [0. 0.3 0.6 0.9 1.2 1.5 1.8]Python의 range() 와 유사하지만, range()와 달리 step의 값으로 실수도 넣을 수 있다.
> Numpy 배열의 주요 속성
- ndarray.shape : numpy 배열의 차원을 튜플 타입으로 반환
- ndarray.dtype : 배열의 자료형을 반환
- ndarray.ndim : dimension 의 차수를 정수로 반환
- ndarray.size : 다차원 배열 요소의 총 개수를 정수값으로 반환
a = np.arange(10) # 0~ 9
print(a)
print(a.dtype) # int32
print(a.shape) # (10,)
print(a.ndim) # 1 ? 1차원 벡터이기 때문에
print(a.size) # 10
배열 생성 - 2
- np.zeros(): 모든 요소가 0으로 이루어지는 지정한 크기의 새로운 배열을 생성
- np.ones() :모든 요소가 1로 만들어진 지정한 크기의 새로운 배열 생성
a = np.zeros(4, dtype= int)# dtype = np.int32) # 4 = 크기
print(a) # [0 0 0 0]
# 1 차원 벡터 , float64 _> default
b = np.zeros((3,3))
print(b) # 3행 3열
# np.zeros_like(ndarray) : 지정된 배열과 같은 형태의 새로운 배열 생성
c = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(np.zeros_like(c)) # 데이터 타입 또한 동일하다
# [[0 0 0]
# [0 0 0]
# [0 0 0]]
print(np.ones((2,3)))
# [[1. 1. 1.]
# [1. 1. 1.]]
print(np.ones_like((c)))np.full()
지정한 크기에 입력한 원소를 전부 채운 배열을 생성
print(np.full((2,2),2)) # 2행 2열을 2로 채운다.
# [[2 2]
# [2 2]]
print(np.full_like(c,0.1, dtype = float))
# c: 3행 3열
# 3행 3열을 0.1 로 채운 행렬이 만들어진다.[문제] 배열 생성
- 1~10 사이의 값에 대해 다음의 조건에 맞는 2차원 배열을 생성하시오.
- 첫 번째 행은 역순으로 나열된 홀수 정수의 요소를 갖고, 두 번째 행은 짝수 정수의 요소를 갖는다.
a = np.array([np.arange(9,0,-2), np.arange(2,11,2)])
print(a)헷갈렸던 () 와 [] 의 차이. 문제를 풀며 구분이 갔다. () : 요소를 넣을때, [] : 배열을 만들때 .. ?
배열 생성 -3
- np.linspace()
start부터 stop의 범위에서 num개를 균일한 간격으로 데이터를 생성하여 배열을 만든다.
print(np.linspace(0,2,9)) # 0 이상 2 이하의 범위 > 9 등분 요소들을 설정
# [0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. ]arange(start, end, step) start ~ end 까지 지정된 step 만큼 띄우는 것이라면 linspace()는 해당 범위 안에서 균등 분할을 한다.
# 삼각함수 그래프 그려보기
x = np.linspace(0, np.pi*2, 100)
y = np.sin(x)
import matplotlib.pyplot as plt
plt.plot(x,y)
plt.show()np.identity() , np.eye()
지정한 크기의 정방 단위 행렬을 생성(정방: 행과 열의 크기가 같은)
정방 단위 행렬은 주대각선의 원소가 모두 1이며 나머지 원소는 모두 0인 정사각형 행렬이다.
그렇지만 np.eye() 는 행과 열의 크기가 다른 단위 행렬도 만들 수 있다.
print(np.identity(2))
print(np.identity(3, dtype= int))
print('='*20)
print(np.eye(3))
print(np.eye(3,4))
print('='*20)
print(np.eye(3,4,1))
print(np.eye(3,4,-1))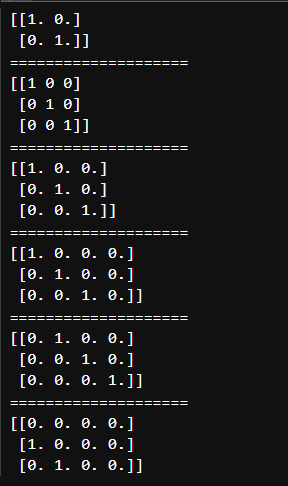
print(np.eye(3,4,1))
# 세 번째 값이 1: 대각선 인덱스 (기본값은 0)
print(np.eye(3,4,-1))
# 양수 값은 위쪽 대각선(열 값 조정), 음수 값은 아래쪽 대각선(행 값 조정)
# 주 대각선의 시작을 정할 수 있음
배열의 변경
- np.reshape() / ndarray.reshape() (차이가 있다면 매개변수의 차이)
원본을 변경하지 않고 배열을 새로운 모양으로 수정한다. 원본 배열의 요소의 개수가 변경할 모양의 배열 요소 개수와 다르면 에러가 발생한다.
a = np.arange(6)
print(a) # [0 1 2 3 4 5]
b = a.reshape(3,2) # np.reshape(b,(3,2)) 동일
print(b)
print(a)
# 원본 배열의 모양은 변하지 않는다.
print('='*30)
c = np.reshape(a,(1,6))
print(c) # 2차원 배열
print("="*30)
d = np.reshape(a,(-1,2)) # **
# 열의 크기를 2로 맞추고 행의 크기는 전체 요소 개수에 맞춰 알아서 지정한다.
print(d)
print("="*30)
e = np.arange(1,11).reshape(2,5)
# arange() 모양 지정은 안됨
print(e)
f = e.reshape((-1,2,1)) # **
# 2행 1열 모양 행렬 깊이는 알아서
print(f)
print("="*30)
g = f.reshape(-1) # 1차원 벡터
# -1 : 행렬의 값이 없으므로 요소를 한줄로 나타내게 된다.
print(g)-1 의 특징
np.reshape(a,(-1,2)) # 열의 크기를 2로 맞추고 행의 크기는 전체 요소 개수에 맞춰 알아서 지정한다.
e.reshape((-1,2,1)) # 2행 1열 모양이고, 행렬 깊이는 알아서 지정
f.reshape(-1) # 1차원 벡터 # -1 : 행렬의 값이 없으므로 요소를 한줄로 나타내게 된다.
- np.resize() / ndarray.resize()
원본 배열을 새로운 shape으로 수정한다. 대상 배열의 요소 개수가 원래 배열과 동일하지 않으면 크기를 강제로 조정한다.
a = np.arange(12)
a.resize((3,4)) # 반환값을 가지지 않는다.
print(a) # 원본의 모양을 변경한다.
print("="*10)
a.resize((4,4)) # (4,4) 모양 튜플의 값으로 전달하는 것
print(a) # 원본과 크기가 달라도 에러가 발생하지 않는다.반환값을 가지지 않기 때문에 print() 안이 아닌 바깥으로 문장을 빼 놓는다.
- ndarray.flatten() / ndarray.ravel()
배열을 1차원으로 만든다.
flatten() 은 배열을 복사해서 1차원으로 변경한다. 원본에 영향을 미치지 않는다.
ravel() 은 원본을 복사하는 것이 아니므로 메모리 낭비가 없다. ( 단, 값을 수정하면 원본도 수정한다.)
a = np.arange(1,5).reshape(2,2)
print(a)
print(a.flatten())
# [[1 2]
# [3 4]]
# [1 2 3 4]
a = np.arange(1,5).reshape(2,2) # 2행 2열
r = a.ravel()
print(r) # [1 2 3 4] # 배열을 1차원으로 만든다.
a[1,1] = 5
print(a)
print(r) # [1 2 3 5] - np.expand_dims()
지정한 축의 위치에 다차원 배열의 차원을 늘려줌.
1차원 -> 2차원 행렬의 경우
a = np.array([1,2])
print(a) # [1 2]
print(a.shape) # (2,) # 튜플로 반환
print("="*10)
# 1차원 벡터에 첫 번째 축(행축)을 추가하여 2앞에 1이 추가 되아 (1,2) 모양으로 확장됨
# 연산이 아니기때문에 1이 아닌 0이다.
b = np.expand_dims(a,axis = 0)
print(b) # [[1 2]] # 2차원 배열
print(b.shape) # (1, 2)
print("="*10)
c = np.expand_dims(a,axis= 1) # 2f행 1열
print(c)
print(c.shape) # (2, 1) 2차원 -> 3차원 행렬의 경우
a = np.arange(1,7).reshape(2,3) # 1차원 -> 2차원
print(a)
print(a.shape) # (2,3)
print("="*10)
# 2차원 행렬을 깊이 축 axis = 0으로 확장
b= np.expand_dims(a,axis = 0) # 3차원 깊이
print(b.shape) # (1, 2, 3) # axis = 0 : 깊이자리에 삽입.
c = np.expand_dims(a,axis = 1) # 행
print(c.shape) # (2, 1, 3) # axis = 1 : 행자리에 삽입.
d = np.expand_dims(a,axis = 2) # 3행 1열 2차원
print(d.shape) # (2, 3, 1) # # axis = 2 : 열자리에 삽입.- np.newaxis() : 차원 증가
ndarray[np.newaxis, :] # 인덱싱 행: 새로운 축 , 열: 모든 데이터 // [: ,np.newaxis] # 새로운 열
a = np.arange(4)
print(a)
print(a.shape) # (4,)
print("="*10)
# a [행, 열]
row_vect = a[np.newaxis, :] # 인덱싱 행: 새로운 축 , 열: 모든 데이터
print(row_vect) # [[0 1 2 3]]
print(row_vect.shape) # 새로운 1 행 4열
print("-"*10)
col_vect = a[: ,np.newaxis] # 새로운 열
print(col_vect)
print(col_vect.shape) # (4, 1) # 4 행 새로운 1열- ndarray.astype()
배열의 데이터 타입을 변경
a = np.array([1,2,3])
print(a)
print(a.dtype) # int32
a_float = a.astype(np.float32)
print(a_float)
print(a_float.dtype) # float32- np.squeeze()
차원 축소시키는 함수( 원본의 원소 개수와 일치되게 하는 것이 중요하다)
a = np.array([ [ [0],[1],[2] ] ]) # 1,3,1 # 차원을 알아보기 위한 띄어쓰기
print(a.shape)(1,3,1)
print("="*10)
b = np.squeeze(a) # 1차원 벡터
print(b.shape)
print(b) # [0 1 2]
print("="*10)
c = np.squeeze(a, axis= 0) # 깊이 축 축소
print(c.shape) # (3, 1)
print(c)
print("="*10)
# d = np.squeeze(a, axis = 1) # 행 축소
# err : 원소의 개수를 다 담지 못 하기 때문
# 원본의 원소 개수와 일치되지 않아서
x = np.array([[1234]]) # 1,1
print(x.shape) # (1, 1)
print("="*10)
y = np.squeeze(x)
print(y.shape) # () : 스칼라값(단일값)으로 변경됨
print(y) # 1234- np.concatenate()
두 개 이상의 배열을 연결한다. 연결을 수행하려면 차원의 수가 같아야 한다.
a = np.arange(1,5).reshape(2,2)
print(a)
print("="*10)
b = np.array([5,6])
print(b)
print("="*10)
# print(np.concatenate((a,b))) # 차원 수가 다르기 때문에 err
print(np.concatenate((a,np.expand_dims(b, axis = 0 ))))
# b: 2, -> 2차원 배열이 되려면 1,2 가 되어야 하므로 axis = 0
# 3개 이상의 배열을 연결 할 수 있다.
b = np.array([[5,6]])
c =np.array([[7,8]])
d = np.concatenate((a,b,c))
print(d)** print(np.concatenate((a,np.expand_dims(b, axis = 0 )))) # b: 2, -> 2차원 배열이 되려면 1,2 가 되어야 하므로 axis = 0
행과 열의 개수에 주의 하며 변경할 축을 설정해야한다.
axis 인수를 설정하면 연결 방향을 정할 수도 있다. (기본값: axis = 0)
행을 기준으로 연결할 때는 열의 개수가 일치해야 하며, 열을 기준으로 연결할 때는 행의 개수가 일치해야한다.
# e = np.concatenate((a,b), axis = 1) # err
e = np.concatenate((a,b.T), axis = 1)
print(e)b.T = 행렬 b를 행과 열의 방향을 바꾼다 = 전치
'국비 교육 > 데이터' 카테고리의 다른 글
| [데이터 분석] Numpy - 4 (실습문제) (0) | 2023.11.08 |
|---|---|
| [데이터 분석] Numpy - 3 (0) | 2023.11.07 |
| [데이터 분석] Numpy -1 (0) | 2023.11.07 |
| [데이터 분석] Seaborn (0) | 2023.11.06 |



