Numerical Python의 약자
고성능의 수치 해석용 python 라이브러리. 대규모의 다차원 배열과 행렬 연산에 필요한 다양한 함수를 제공
Python 다차원 배열의 이해
> 숫자 자료형
# 세 명의 학생의 수학과목 점수 설정
math1 = 11
math2 = 12
math3 = 13
# 합과 평균 구하기
total = math1 + math2 + math3
average = total / 3
print(f"수학점수 합: {total}")
print(f"수학점수 평균: {average:.2f}")새로운 학생이 전학을 온다면? 어떻게 할 것인가
> 리스트 자료형
math_list = [11,12,13]
math_list.append(14) # 새로운 학생
total = 0
average = 0
for math in math_list:
total += math
average = total/len(math_list)
print(f"수학점수 합: {total}")
print(f"수학점수 평균: {average:.2f}")리스트로 만들어 관리를 한다면 숫자 자료형보다 쉬운 변경이 가능해진다.
그런데 만약 시험문제에 오류가 발견되어 모든 학생의 점수를 1점씩 올려줘야 하는 상황이 발생한다면 어떻게 처리할 것인가?
math_list = [ math + 1 for math in math_list]
print(math_list)파이썬에서는 비교적 쉬운 방법인 '리스트 컴프리헨션'으로 해결하면 된다.
Numpy로 구현한 다차원 배열
Numpy 를 사용하면 중첩된 자료구조를 효율적으로 다룰 수 있다. import numpy as np 형태로 사용하는게 일반적이다.
import numpy as np
math_ndarray = np.array([[11,12,13],[21,22,23],[31,32,33]]) # 리스트를 -> np의 다차원 배열
print(math_ndarray)
print(type(math_ndarray)) # 다차원 배열이라고 부름각 원소에 1을 더하려면 ?
new_ndarray = math_ndarray + 1
print(new_ndarray) # for 문을 쓰지 않고도 모든 원소에 단일값을 더할 수 있다.리스트 자료형 보다 쉽고 간편한 방법으로 해결되는 것을 알수 있다.
# 전체 합 구하기
np.sum(math_ndarray)
# 전체 평균 구하기
np.mean(math_ndarray)
# 행의 평균 구하기
np.mean(math_ndarray, axis= 1) # array([12., 22., 32.])
# 열의 평균 구하기
np.mean(math_ndarray, axis= 0) # array([21., 22., 23.])Numpy axis(축) 정리
ndarray.shape() : 결과값이 튜플
# ndarray.shape() 예시
import numpy as np
array1 = np.array([[1,2], [3,4]])
print(array1)
# [[1 2]
# [3 4]]
print(array1.shape) # 행,열 값 = (2,2)
print("-"* 10)
array2 = np.array([[[1,2,3],
[4,5,6]], # 2,3 2차원 배열
[[7,8,9],
[10,11,12]]
]) # 2,3열 2가지 판
print(array2)
print(array2.shape)> 1차원 벡터: (원소개수,)
> 2차원 행렬: (행,열)
2차원인 경우 axis 값이 (0,1)이며, axis 0 = 행, 1 = 열 을 나타낸다.
> 3차원 행렬: (깊이, 행, 열)
3차원인 경우 axis 값이 (0,1,2)이며, axis 0 = 깊이, axis 1 = 행, axis 2 = 열 을 나타낸다.
근데 왜 위에 코드에서 행의 평균을 구할때 1을 쓸까?
실제로 행에 대한 집계값 계산은 방향에 맞춰 축의 값을 1로 지정하기 때문이다.
a = [[1, 2], 행에 대한 계산 1+2 = 3 , 3+ 4 =7 => 가로로 더함 => axis = 1(열)
[3, 4]] 열에 대한 계산 1+3 = 4, 2 + 4 = 6 => 세로로 더함 => axis = 0(행)
하지만 이러한 행,열을 다르게 구분하게 되는 때는 1. 행렬의 연산 2. 행렬 모양 변경(결합) 두 가지 중에 1. 연산에만 해당된다.
print('2차원 배열의 axis = 0 기준 합', end = '')
print(np.sum(array1,axis= 0)) # 2차원 배열의 axis = 0 기준 합[4 6]
print('2차원 배열의 axis = 1 기준 합', end = '')
print(np.sum(array1,axis= 1)) # 2차원 배열의 axis = 1 기준 합[3 7]
print('3차원 배열의 axis = 0 기준 합')
print(np.sum(array2,axis= 0))
# 3차원 배열의 axis = 1 기준 합
# [[ 8 10 12]
# [14 16 18]]
print('3차원 배열의 axis = 1 기준 합')
print(np.sum(array2,axis= 1))
# 3차원 배열의 axis = 1 기준 합
# [[ 5 7 9]
# [17 19 21]]
print('3차원 배열의 axis = 2 기준 합')
print(np.sum(array2,axis= 2))
# 3차원 배열의 axis = 2 기준 합
# [[ 6 15]
# [24 33]]3차원 행렬은 (깊이, 행, 열) 로 되어 있다.
axis = 0 : 깊이 = 서로 상응 하는 원소 끼리 더한다.
axis = 1 : 열의 합 , axis = 2: 행의 합이다.
Numpy 특징
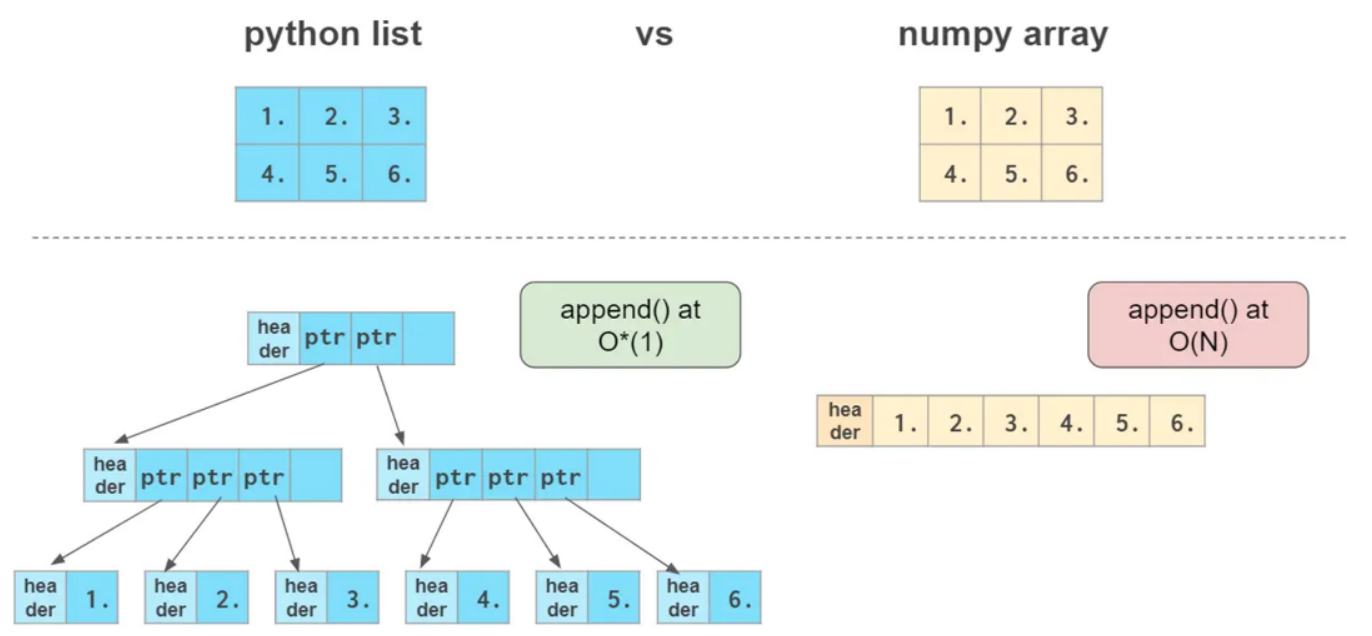
> Python list가 느린 이유
파이썬 리스트는 포인터의 배열이다. 참조형 데이터 이기 때문이다.
따라서 각각의 객체가 메모리 여기저기에 흩어져 있다. => 캐시 활용이 어렵다.
(캐시 : 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 자주 사용되는 데이터를 가져다 쓰는 장소(데이터의 재활용))
>Numpy ndarray가 빠른 이유
타입을 명시하여 원소의 배열로 데이터를 유지한다. 다차원 데이터도 연속된 메모리 공간이 할당된다.
'풀스택 개발 학습 과정 > 데이터' 카테고리의 다른 글
| [데이터 분석] Numpy - 3 (0) | 2023.11.07 |
|---|---|
| [데이터 분석] Numpy - 2 (0) | 2023.11.07 |
| [데이터 분석] Seaborn (0) | 2023.11.06 |
| [데이터 시각화] matplotlib - 2 (0) | 2023.11.04 |



