[머신러닝] 분류분석 : 의사 결정 트리, 앙상블 러닝 - Bagging
의사결정 트리 Decision Tree
의사 결정 규칙과 그 결과들을 트리구조로 도식화한 의사결정 지원 도구의 일종이다.
직관적으로 이해하기 쉬운 알고리즘이다.

루트노드 : 최상위 노드 / 규칙 노드: 규칙 조건 / 리프 노드 : 결정된 클래스 값
새로운 규칙 조건마다 서브 트리가 생성된다.
하지만 많은 규칙은 분류를 결정하는 방식이 더욱 복잡해진다는 의미인 것으로 트리의 깊이가 너무 깊어지면 예측성능이 저하될 수 있다 (과적합의 위험이 있기 때문)
때문에 가능한 적은 노드로 높은 예측 정확도를 가질 수 있도록 결정노드의 규칙을 정해야한다.
의사결정 트리 알고리즘 구조
- 정보함수: 정보 가치를 반환하는데 발생할 확률이 적은 사건일수록 정보의 가치가 크다.
l(x) = log21/p(x)
- 정보획득량: 어떤 사건이 얼마 만큼의 정보를 줄 수 있는지 수치화하는 값
1 - 엔트로피 지수 -> 결정트리는 이 정보획득량으로 분할기준을 정한다.
분류 전 엔트로피가 1 이었는데 분류 후에도 엔트로피가 1이라면 정보획득이 전혀 이루어지지 않았다고 본다.
0 으로 감소하면 모든 값들을 분류할 수 있게 되었다는 것이다.
info gain = H(S) - ∑p(x)H(x)
- 엔트로피: 무질서도를 정량화해서 표현한 값(주어진 데이터 집합의 혼잡도)
서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다.
H(x) = - ∑p(x)l(x)
- 지니계수 : 지니계수가 낮을수록 데이터의 순도가 높은 것으로 해석하기 때문에 낮은 속성을 기준으로 분할한다.
경제학에서 불평등 지수를 나타낼때 사용하는 계수이다. 0이 가장 평등하고 1이 가장 불평등하다.
의사결정트리 파라미터
의사결정 트리 학습과정
가지치기 pruning :
모든 잎의 엔트로피가 0이 될때까지 분류하면 기존 데이터는 적합한 분류가 될 수 있지만 새로운 데이터는 제대로 분류하지 못하게 될 수도 있다.
때문에 모든 노드를 분리한 뒤 분기를 적절히 합치는 과정을 거쳐 일반화 해주는 것을 의미한다.
앙상블 러닝 Ensemble Learning
주어진 자료에서 여러개의 예측모델을 학습한 다음 최종 예측 모델을 사용하여 정확도를 높이는 기법.
단일모형보다 성능이 좋다.
앙상블 러닝 종류
>> 보팅 Voting
동일 데이터셋에 대하여 여러개의 분류기(model)를 사용하여 학습을 진행한다.
- Hard Voting : 다수결 투표
- Soft Voting : 각 레이블의 예측 확률의 평균으로 최종 분류
>> 배깅 Bagging
서로 다른 데이터셋에 하나의 모델을 다양하게 학습 'Bootstrap + Aggregating' (보팅과 반대)
- Bootstrap : 복원 랜덤 샘플링 방식으로 전체 데이터의 일부분을 뽑는 방식
- Aggregating : 집계 (분류분석: 투표/ 회귀분석: 예측값 평균)
model : RandomForest
>> 부스팅 Boosting
제대로 분류되지 않은 예측력이 약한 모형들을 결합하여 강한 예측 모형을 만드는 것
[실습] 보스톤 집값 예측 Bagging - Regressor
패키지 로드
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor # 의사결정나무(회귀분석적용)
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, r2_score
import pandas as pd
import numpy as np
데이터 로드
규제와 관련된 실습을 통해 한 번 다뤄본 데이터셋이므로, 크게 데이터는 확인하지 않았다
boston = pd.read_csv('./dataset/HousingData.csv')
boston.head()
boston.dropna(inplace= True)
x = boston.drop('MEDV',axis= 1)
y = boston['MEDV']
학습, 평가 데이터 분할 및 스케일링
해당 데이터는 분류분석이 아닌 회귀분석으로 풀이하는 방법이기 때문에 stratify 는 작성하지 않는다.
scaled_x = StandardScaler().fit_transform(x)
x_train, x_test, y_train,y_test = train_test_split(scaled_x, y, test_size= 0.3,
random_state= 10)
모델 생성 및 검증
model = RandomForestRegressor(n_estimators=150, random_state= 0) # n_estimators: 분류기 개수
# bagging = 복원 추출 -> 랜덤값 고정
model.fit(x_train,y_train)y_hat = model.predict(x_test)
print(f'RMSE = {np.sqrt(mean_squared_error(y_test,y_hat)):.3f}')
print(f'R2 score = {r2_score(y_test,y_hat):.3f}')
# 이전 결과
# 결정계수: 0.782 , RMSE = 3.50RMSE = 2.290
R2 score = 0.906이전 규제 실습때 보다 낮은 RSME 값 과 높은 r - squared 값을 가진 것을 알수 있다.
RMSE Root Mean Squared Error : 평균 제곱근 오차. MSE 값의 왜곡이 줄어들므로 값이 낮을수록 좋다.
GridSearchCV를 이용한 파라미터 튜닝
GridSearchCV 란 모델의 하이퍼 파라미터의 값을 리스트로 입력하면 값에 대한 경우의 수마다 예측 성능을 측정 평가하여 비교하면서 최적의 하이퍼 파라미터 값을 찾는 과정을 진행하는 것을 말한다 (해당 코드에서는 zip 함수로 처리하였다.)
from sklearn.model_selection import GridSearchCV
params ={'n_estimators': [10, 20, 50, 100, 200, 250],
'max_features': [2, 4, 6, 8, 10], # feature 의 수 (None 이 default)
'bootstrap': [True, False]} # True: 복원추출
model = RandomForestRegressor()
gs = GridSearchCV(model, params, cv = 5, scoring='neg_mean_squared_error')
gs.fit(scaled_x,y)
print('Best Parameters =', gs.best_params_)Best Parameters = {'bootstrap': False, 'max_features': 6, 'n_estimators': 10}
GridSearchCV 통해 알게된 best esimator(의사결정나무 개수)의 조건으로 평가 해보기
y_hat = gs.best_estimator_.predict(x_test) # 위의 조합에서의 estimator
print(f'RMSE = {np.sqrt(mean_squared_error(y_test,y_hat)):.3f}')
print(f'R2 score = {r2_score(y_test,y_hat):.3f}')RMSE = 0.000
R2 score = 1.000회귀분석에서의 결정계수(r2-score)는 자료에 대한 추정된 모형의 적합도를 의미한다.
따라서 결정계수의 값이 1(100%)에 가까울수록 모형이 자료를 잘 설명하고 있다고 할 수 있기 때문에 해당 알고리즘은 완벽히 자료를 설명하고 있다.
이후 이러한 저장된 훈련 방법을 사용하여 다른 OS 에서 적용할 것을 대비하여 실습해보기
최적화된 모형 저장
pickle을 사용하여 binary형태(용량이 매우 작아진)로 파일을 저장한다 -> ' pickle.dump()'
import pickle # 직렬화
with open('model.dat','wb') as f:
pickle.dump(gs.best_estimator_,f)
print('모델 저장 완료') # 학습 결과를 담고 있는 파일
picke.load()는 컴퓨터에 저장되어 있는 피클 파일을 객체로 불러와 그 값으로 예측한 것이다.
import os
if os.path.exists('model.dat'):
with open('model.dat','rb') as f:
loaded_model = pickle.load(f)
y_hat = loaded_model.predict(x_test)
print(y_hat[:10])
[실습] 와인 품종 분류 Bagging - Classifier
패키지로드
분류분석이기 때문에 평가지표가 달라진다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report
데이터 로딩 및 확인
wine = load_wine()
# print(wine.DESCR)
x= wine.data
y = wine.target
df = pd.DataFrame(x, columns= wine.feature_names)
df['class'] = y
df.head()
print(df['class'].value_counts())class
1 71
0 59
2 48
Name: count, dtype: int64종속변수인 품종의 독립값 확인
데이터 스케일링 및 분할
'stratify= y' : 분류분석에 넣어야함
scaled_x = StandardScaler().fit_transform(x)
x_train, x_test, y_train, y_test = train_test_split(scaled_x, y, test_size= 0.3,
random_state= 10, stratify= y)
모델 생성 및 평가
model = RandomForestClassifier() # 배깅을 이용한 앙상블 개수
model.fit(x_train,y_train)
y_hat = model.predict(x_test)
con_mat = confusion_matrix(y_test,y_hat)
print(con_mat) # 오류 1개 : 정확도 높을 예정
report = classification_report(y_test,y_hat)
print(report)[[17 1 0]
[ 0 21 0]
[ 0 0 15]]오류 1개 존재하는 것으로 보아 정확도 높을 것이라 예측 가능하며,
classification_report 를 통해 그것이 사실인 것을 확인하였다.
precision recall f1-score support
0 1.00 0.94 0.97 18
1 0.95 1.00 0.98 21
2 1.00 1.00 1.00 15
accuracy 0.98 54
macro avg 0.98 0.98 0.98 54
weighted avg 0.98 0.98 0.98 54
트리 시각화
1. 시각화 하고자 하는 트리를 파일로 저장
하기 위해서는 'export_graphviz' 패키지를 로드해야 한다.
from sklearn.tree import export_graphviz
estimator = model.estimators_[2] # 전체 모형을 다 가져옴 -> 그 중 세 번쨰
# print(len(estimator)) # 의사결정나무가 100개 들어있다.
export_graphviz(estimator, out_file= 'tree.dot',
class_names= wine.target_names, # class_names= 분류값의 이름
feature_names= wine.feature_names,
# max_depth= 3, # max_depth= 표현하고 싶은 최대 나무 깊이
precision= 3, # 소수점 정밀도
filled= True, # 클래스별 색 채우기
rounded= True) # 박스모양을 둥글게
# 3번째 의사결정 나무를 파일로 저장
2. 시각화
진행하기 위해서는 graphviz 패키지 설치가 필요하다.
anaconda 프롬포트 실행 >> coda install python-graphviz >> 주피터랩 재기동
# flovanoids <= - 0.76 : 자식노드를 만들기 위한 규칙 조건
# gini : 현재 노드의 불순도. 얼마나 다양한 클래스의 샘플들이 섞여있는지 나타내는 계수. 마지막은 gini = 0 (순도가 높다)
# samples: 현 노드의 규칙에 해당하는 데이터의 수
# value : 각 클래스에 해당하는 데이터의 수
# class: value 값 중 다수의 값을 갖는 클래스 (헤당 클래스로 분류가 된다.)
# 2. 시각화
import graphviz
with open('tree.dot') as f:
tree = f.read()
graphviz.Source(tree)
하이퍼 파라메터 튜닝
가능한 모든 하이퍼 파라미터 조합에 대해 교차 검증을 사용해 평가
from sklearn.model_selection import GridSearchCV
params = {'max_depth': [3,4,5,6,10],'min_samples_split':[3,6,9,10,20,30]}
# refit-true : 가장 좋은 파라메터 설정으로 재학습한 후 best_estimator_ 에 저장(de)
gs = GridSearchCV(model, params, scoring= 'accuracy', cv = 5)
gs.fit(x,y)print('최적 파라미터', gs.best_params_)
print(f'최적 파라미터 정확도 {gs.best_score_:.3f}')최적 파라미터 {'max_depth': 10, 'min_samples_split': 6}
최적 파라미터 정확도 0.989
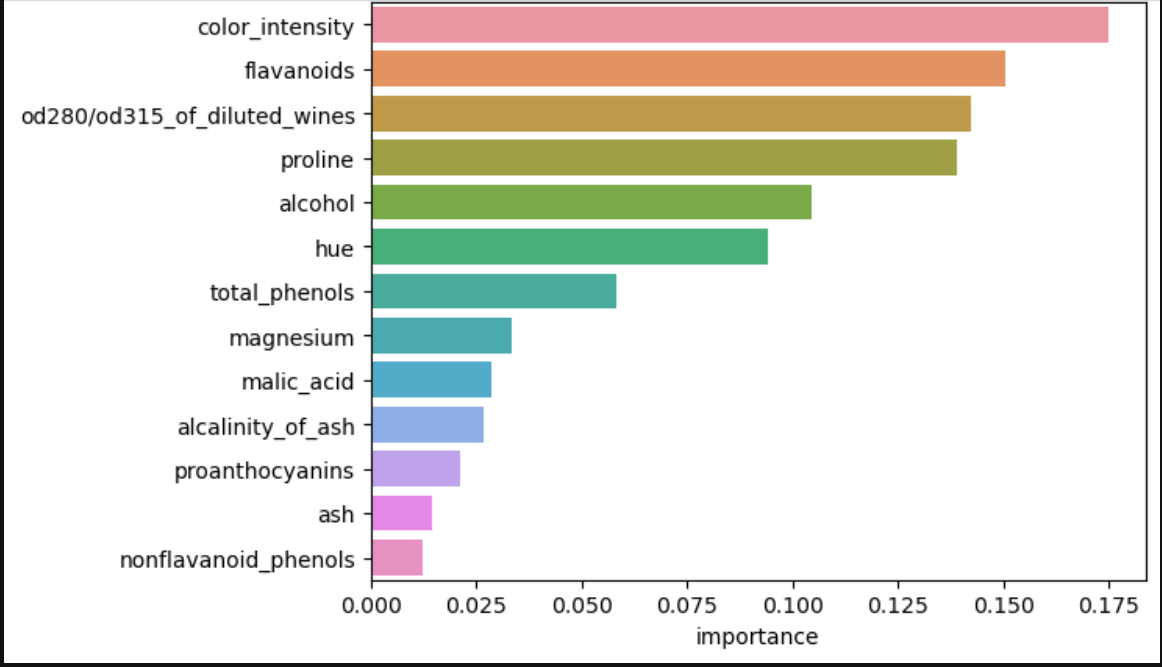
Feature Importance
의사결정 나무 알고리즘이 학습을 통해 규칙을 정하는데 있어 피처의 중요한 역할 지표를 제공하는 속성
일반적으로 값이 높을수록 해당 피처의 중요도가 높다는 의미로 해석된다.
정확한 예측을 만들기 위한 각 특성의 상대적인 중요도를 확인하는 방법이다.
im = gs.best_estimator_.feature_importances_
imarray([0.10440395, 0.02859544, 0.01451806, 0.0266641 , 0.0333574 ,
0.0582031 , 0.15044891, 0.01250173, 0.02104961, 0.17485384,
0.09417256, 0.14228125, 0.13895004])importance = { k:v for k,v in zip(wine.feature_names, im)}
df_importance = pd.DataFrame(pd.Series(importance), columns= ['importance'])
df_importance = df_importance.sort_values('importance', ascending= False)
df_importancefeature = 특징적인 컬럼을 뜻하는 것 같다.
중요도 시각화
import seaborn as sns
import matplotlib.pyplot as plt
sns.barplot(df_importance,x = 'importance', y = df_importance.index) # y = df_importance.index 독립변수명을 배치
plt.show()