[머신러닝] 분류분석 : [이지분류] 로지스틱 회귀분석 - (실습) 유방암 확률 예측, 개인 신용도 기반 대출 가능 여부 예측
유방암 확률 예측
패키지 로딩
해당 데이터는 sklearn 에 저장되어있는 유방암 환자 데이터 이다.
from sklearn.datasets import load_breast_cancer # 유방암환자 데이터 제공
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_curve, roc_auc_score, confusion_matrix
from sklearn.model_selection import train_test_split
import pandas as pd데이터 로드 및 확인
breast = load_breast_cancer()
# print(breast.DESCR) # 데이터셋 설명 _ class : 종속변수 (두 가지 카테고리 : 이진분류)
df = pd.DataFrame(breast.data, columns= breast.feature_names) # 독립변수 값만 데이터 프레임
df['target'] = breast.target # 0,1 로 이루어진 데이터
print(df.shape)
display(df.head())Bunch의 자료구조 형태이기 때문에 pandas 를 이용하여 데이터 프레임으로 변환시킨다.
이진 분류 데이터 이므로 target = 종속변수의 값이 0,1 로 이루어져 있다.
print(df['target'].value_counts())
df.isna().sum()
df.describe()target
1 357
0 212
Name: count, dtype: int64
종속변수와 독립변수 분리
# 데이터 프레임으로도 읽을 수 있음
data_x = breast.data
data_y = breast.target종속변수 = target, 독립변수 = data
데이터 스케일링
scaled_data = StandardScaler().fit_transform(data_x)
학습, 평가데이터 분리
x_train,x_test,y_train,y_test = train_test_split(scaled_data, data_y,
test_size= 0.3, random_state= 0, stratify= data_y)train_test_split : 랜덤하게 분할되기 때문에 0 과 1이 동일하게 분류되지 않는다.
stratify= data_y 를 포함시켜 종속변수 분포 개수 맞춰 학습데이터와 평가 데이터를 동일한 분포로 분할시켜 주어야 한다.
모델 생성
model = LogisticRegression() # 회귀계수를 최적화하기 위한 파라메터를 넣을 수 있음
model.fit(x_train, y_train)
# 가중치
print('추정계수(가중치):', model.coef_) # 30개 컬럼의 가중치
# 양수면 양의 상관관계에 영향, 음수면 음의 상관관계
print('절편:', model.intercept_)추정계수(가중치): [[-0.54406091 -0.41605507 -0.51991133 -0.59308816 0.0027904 0.41939012
-0.78884789 -1.02290774 -0.15221315 0.37699245 -1.07237296 -0.06165012
-0.54319278 -0.69191037 -0.21537603 0.61125449 0.11034357 -0.26876198
0.49779553 0.42281321 -0.97636344 -1.08977767 -0.82614726 -0.86970513
-0.55575019 -0.15928048 -0.62816926 -0.7691139 -0.67505294 -0.73082045]]
절편: [0.23582794]
LogisticRegression() = 회귀계수를 최적화하기 위한 파라메터를 넣을 수 있음
회귀계수 최적화 옵션
- solver : 최적화 문제에 사용될 알고리즘
- 'lbfgs' : 기본값 (별도 지정없으면 이 알고리즘을 통해 분류모형을 만듦), CPU 코어수가 많다면 최적화를 병렬로 수행.
- 'liblinear' : 적은 데이터에 적합한 알고리즘(병렬 최적화를 수행할 수 없다)
-'sag','saga' : 확률적 경사하강법을 기반으로한 알고리즘으로 대용량 데이터에 적합
- 확률적 경사하강법: 임의로 샘플링하여 그것에 대한 손실함수를 계산 후 경사하강법 적용(데이터 처리속도가 빠르다)
- 'newton-cg','sag','saga','lbfgs' 만 다항 손실을 처리 (즉, 멀티클래스 분류 모델에 사용가능)
- solver 에 따른 규제 지원 사항
- newton-cg,lbfgs, sag : L2 규제 적용
- liblinear, saga : L1,L2 규제 적용
multi_class : 다중 클래스 분류문제의 상황에서 어떤 접근방식을 취할지 결정
- 'ovr' : 이진분류기인 simoid 함수를 이용하여 결과를 예측
- 'multinomial' : softmax 확률값으로 다중분류 수행
(softmax: 종속변수 값이 3개 이상일 경우 범주별 확률 분포값으로 결과를 반환, 각 범주별 확률의 합은 1이다.)
- C : 규제의 강도의 역수 : C값이 작을수록 모델이 단순해진다(규제강도가 더 강해진다)
- max_iter : solver 가 결과를 수렴하는데 필요한 반복 횟수 지정 (default : 100)
(반복횟수가 적은 경우 경고메세지가 나타날 수 있다. => 반복횟수를 증가시키면 됨)
모델 예측
y_hat = model.predict(x_test)
print('정답:', y_test[:20])
print('예측:' , y_hat[:20])
# 오분류표를 만들면 => 혼동매트릭스정답: [0 0 0 1 0 1 0 0 0 0 0 1 1 1 0 0 0 1 0 0]
예측: [0 1 0 1 0 1 0 0 0 0 1 1 1 1 0 0 0 1 0 0]
모델 예측 : Confusion Matrix
혼동행렬 함수는 행을 True, 열을 Predict 값으로 이용
음성과 양성의 구분은 별도의 레이블을 지정하지 않으면, 레이블 값의 정렬된 순서로 사용한다.
0: Negative , 1: positive (첫번째 나온 값을 Negative 라고 지정한다.)
predict
-------------------
Negative | Positive
-------------------
|N| TN | FP
true |-|---------------
|P| FN | TP
-------------------
matrix = confusion_matrix(y_test,y_hat)
print(matrix)[[ 61 3]
[ 4 103]]
평가지표
# (61+103) / (61+3+4+103)
print(f'정확도: {accuracy_score(y_test,y_hat):.2f}')
# 103 / (3+103)
print(f'정밀도: {precision_score(y_test,y_hat):.2f}')
# 103 / (4+103)
print(f'민감도(재현율): {recall_score(y_test,y_hat):.2f}')정확도: 0.96
정밀도: 0.97
민감도(재현율): 0.96pred_proba_positive = model.predict_proba(x_test)[:,1] # positive 만 # predict_proba 예측을 성공한 확률값
# print(pred_proba_positive) # 임계값 기준 1 | 0
fpr, tpr, thresholds = roc_curve(y_test, pred_proba_positive) # positive 라고 예측한 확률값 필요
roc_data = pd.DataFrame(np.concatenate([fpr.reshape(-1,1), tpr.reshape(-1,1), np.round(thresholds.reshape(-1,1),3)], axis = 1),
columns= ['FPR','TPR','THRESHOLDS'])
display(roc_data) # 거짓 양성율과 참 양성율의 변화값
# TPR 이 높을때 FPR이 낮은 것이 차이가 큰 것 = 최적의 임계값
print(f'AUC: {roc_auc_score(y_test,pred_proba_positive):.3f}')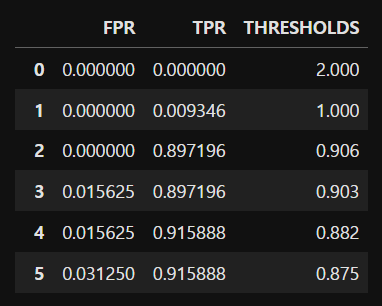
ROC curve 그리기
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.show()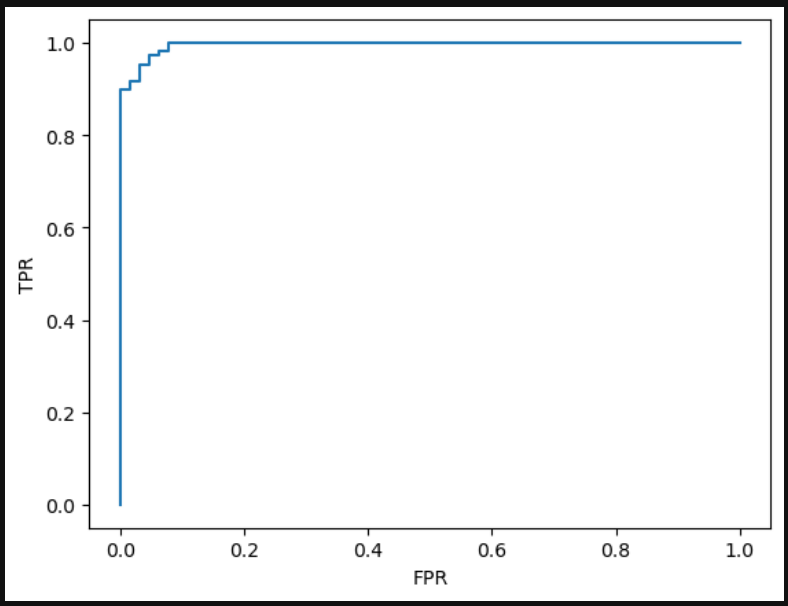
임계값 변화에 따른 재현율과 정밀도 변화 확인
# 실제 양성을 양성이라고 판단한 비율 (TPR)과 음성을 양성이라고 잘못 판단한 위양성율(FPR)의 차이가 가장 큰 경우의 임계치가 최적의 임계값이다.
optimal_threshold = thresholds[np.argmax(tpr-fpr)]
print(f'최적의 임계값: {optimal_threshold:.3f}')최적의 임계값: 0.493
분류결과를 하나의 레포트로 보여주는 classification_report() 확인하기
from sklearn.metrics import classification_report # 분류결과를 하나의 레포트로 보여주는
def threshold_filter(prob,threshold): # 확률값, 임계치
return np.where(prob > threshold , 1 , 0) # 특정 조건_ 넘으면 1, 아니면 0
pred_1 = threshold_filter(pred_proba_positive, 0.5)
pred_2 = threshold_filter(pred_proba_positive, 0.7)
pred_3 = threshold_filter(pred_proba_positive, 0.3)
print(classification_report(y_test,pred_1))
print('='* 60)
print(classification_report(y_test,pred_2))
print('='* 60)
print(classification_report(y_test,pred_3))precision recall f1-score support
0 0.94 0.95 0.95 64
1 0.97 0.96 0.97 107
accuracy 0.96 171
macro avg 0.96 0.96 0.96 171
weighted avg 0.96 0.96 0.96 171pred 1의 값만 가져왔다.
solver 별 성능평가 비교
solvers = ['lbfgs','liblinear','newton-cg','sag','saga']
for solver in solvers:
model = LogisticRegression(solver = solver, max_iter= 600)
model.fit(x_train, y_train)
y_hat = model.predict(x_test)
pred_proba_positive = model.predict_proba(x_test)[:,1]
print(f'solver: {solver}, accuracy: {accuracy_score(y_test,y_hat):.3f}, auc: {roc_auc_score(y_test,pred_proba_positive):.3f}')solver: lbfgs, accuracy: 0.959, auc: 0.996
solver: liblinear, accuracy: 0.959, auc: 0.996
solver: newton-cg, accuracy: 0.959, auc: 0.996
solver: sag, accuracy: 0.959, auc: 0.996
solver: saga, accuracy: 0.959, auc: 0.996데이터의 크기가 작아 알고리즘 별 유의미한 차이가 없다.
개인 신용도 기반 대출 가능 여부 예측
패키지 로딩
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_curve, roc_auc_score, confusion_matrix
from sklearn.model_selection import train_test_split
import pandas as pd
데이터 로드 및 확인
df = pd.read_csv('./dataset/Personal_Loan.csv')
print(df.shape)
display(df.head())
df.isna().sum()
df.describe()
데이터 전처리
df = df.drop(['ID','ZIP Code'], axis= 1)
data_x = df.drop('Personal Loan', axis = 1)
data_y = df['Personal Loan']
print(data_y.value_counts())이진 분류값 체크
Personal Loan
0 4520
1 480
Name: count, dtype: int64이미 정제되어있는 데이터이기 때문에 스케일링은 따로 안 해줘도 된다.
훈련, 평가데이터 분할
x_train, x_test,y_train,y_test = train_test_split(data_x, data_y,
test_size= 0.3, stratify= data_y)
시각적으로 보기 편하게 지수표현의 식을 실수로 보일 수 있게 변경하였다.
np.set_printoptions(precision = 3, suppress= True) # 지수표현식 -> 실수로
모델 생성
max_iter=2000 번의 훈련을 수행한다.
model = LogisticRegression(max_iter=2000) # 회귀계수를 최적화하기 위한 파라메터를 넣을 수 있음
model.fit(x_train, y_train)
coef = model.coef_.squeeze(axis = 0)
print('추정계수(가중치): ', coef)
# 회귀계수 해석
# 로지스틱 회귀계수는 지수변환(exp())을 해주면 odds 비가 나온다.(오즈비 = 성공확률/실패확률)
odds_rate = np.exp(model.coef_).squeeze(axis = 0)
coef_df = pd.DataFrame({'가중치':coef, 'Odds비':odds_rate}, index= data_x.columns)
coef_df
# 가중치가 큰 값은 대출 여부의 큰 영향이 있다.
# 오즈비가 큰 경우는 대출 승인 여부가 높다.추정계수(가중치): [-0.043 0.052 0.055 0.621 0.093 1.624 0. -0.707 3.327 -0.48
-0.972]
odds 비의 값과 비교하여 대출 가능여부 결과값 확인하기
print(df[df['Personal Loan'] == 0]['Education'].mean()) # 대출 거부 사람들의 평균값
print(df[df['Personal Loan'] == 1]['Education'].mean()) # 대출 승인 사람들의 평균값1.8435840707964601
2.2333333333333334print(df[df['Personal Loan'] == 0]['Income'].mean()) # 대출 거부 사람들의 평균값
print(df[df['Personal Loan'] == 1]['Income'].mean()) # 대출 승인 사람들의 평균값66.23738938053097
144.74583333333334
모델 예측 및 성능 측정
시각적으로 편하게 보기 위해 컬럼명과 인덱스명을 설정해주었다.
y_hat = model.predict(x_test)
cf = confusion_matrix(y_test,y_hat)
cf_df = pd.DataFrame(cf, index= [['actual', 'actual'],['대출불허(0)','대출승인(1)']],
columns=[['predict','predict'],['대출불허(0)','대출승인']])
display(cf_df)
print(f'정확도: {accuracy_score(y_test,y_hat):.3f}')
print(f'정밀도: {precision_score(y_test,y_hat):.3f}')
# 상당히 준수한 성능
print(f'민감도(재현율): {recall_score(y_test,y_hat):.3f}')정확도: 0.951
정밀도: 0.832
민감도(재현율): 0.618
proba_posi = model.predict_proba(x_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, proba_posi)
print(f'AUC :{roc_auc_score(y_test, proba_posi):.3f}')
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()AUC :0.954
교차검증
과적합 여부 판단하기 위해 수행
from sklearn.tree import DecisionTreeClassifier # 분류모형
from sklearn.model_selection import cross_val_score, cross_validate
#model = DecisionTreeClassifier(random_state= 1)
score = cross_val_score(model, data_x, data_y)
scores = cross_validate(model, data_x,data_y, cv= 10, scoring=['accuracy','precision','roc_auc'])
for key,val in scores.items():
print('평가지표:', key)
print(f'평균값: {np.mean(val):.3f}')
print('='*30)
# 과적합이 발생하지 않은 모형이다.평가지표: fit_time
평균값: 0.239
==============================
평가지표: score_time
평균값: 0.006
==============================
평가지표: test_accuracy
평균값: 0.950
==============================
평가지표: test_precision
평균값: 0.810
==============================
평가지표: test_roc_auc
평균값: 0.958
==============================