* IMDB 영화평 데이터 : 정답을 가지고 있는데이터
지도학습 기반 감성분석
데이터 로딩 및 확인
import pandas as pd
review_df = pd.read_csv('./labeledTrainData.tsv',header= 0, sep='\t')
print(review_df.shape)%alias_magic
review_df.head()(25000, 3)
review_df['review'][0]"With all this stuff going down at the moment with MJ i've started listening to his music, watching the odd documentary here and there, watched The Wiz and watched Moonwalker again. Maybe i just want to get a certain insight into this guy who i thought was really cool in the eighties just to maybe make up my mind whether he is guilty or innocent.(중략)
데이터 전처리
br태그 삭제, 알파벳이 아닌 문자 삭제
review_df['review'] = review_df['review'].str.replace('<br />',' ')
review_df['review'][0]"With all this stuff going down at the moment with MJ i've started listening to his music, watching the odd documentary here and there, watched The Wiz and watched Moonwalker again. 해당 원문 안에 원래 <br> 태그가 존재했지만, 영어만 남기고 그 외(구두점, 이모티콘, 특수문자 등)를 제외시킴
import re
review_df['review'] = review_df['review'].apply(lambda x:re.sub('[^a-zA-Z]+',' ',x))
# lambda x:re.sub('[^a-zA-Z]+',' ',x) re.sub(패턴식, 바꿀식, 오리지널 데이터)
review_df['review'][0]'With all this stuff going down at the moment with MJ i ve started listening to his music watching the odd documentary here and there watched The Wiz and watched Moonwalker again Maybe i just want to get a certain insight into this guy who i thought was really cool in the eighties just to maybe make
학습/평가 데이터 분리
from sklearn.model_selection import train_test_split
x = review_df['review']
y = review_df['sentiment'] # 감성값
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size= 0.3, stratify= y, # 종속변수의 분포를 동일 비율로
random_state= 0)
피처 벡터화
ngram_range=(1,2) 로 설정
from sklearn.feature_extraction.text import CountVectorizer
from nltk.corpus import stopwords
cnt_vect = CountVectorizer(stop_words=stopwords.words('english'), ngram_range=(1,2))
cnt_vect.fit(x_train)
x_train_cnt_vect = cnt_vect.transform(x_train)
x_test_cnt_vect = cnt_vect.transform(x_test)
모델 학습 및 평가
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
model = LogisticRegression(solver='liblinear')
model.fit(x_train_cnt_vect, y_train)
y_hat = model.predict(x_test_cnt_vect)
pred_prob = model.predict_proba(x_test_cnt_vect)[:,1]
print(f'정확도: {accuracy_score(y_test,y_hat):.3f}')
print(f'AUC: {roc_auc_score(y_test,pred_prob):.3f}')정확도: 0.890
AUC: 0.952
비지도 학습 기반 감정 분석
WordNet Synset 과 SentiWordNet SentiSynset 클래스 이용
NLTK 의 모든 데이터셋과 패키지 다운로드
import nltk
nltk.download('all')WordNet 주요 기능 확인
WordNet : 시맨틱(문맥상 의미)분석을 제공하는 어휘사전
synsets(): 하나의 단어가 가질 수 있는 여러가지 시맨틱 정보를 Synset() 객체로 반환
synset 객체 형식: aaaa.b.c --> a: 단어이름, b: 품사, c: 같은 품사 그룹의 인덱스
from nltk.corpus import wordnet as wn
term = 'present'
synsets = wn.synsets(term) # 리스트 형태로 반환
print(type(synsets))
print(len(synsets)) # 18개의 의미를 가지고 있다
print(synsets)<class 'list'>
18
[Synset('present.n.01'), Synset('present.n.02'), Synset('present.n.03'), Synset('show.v.01'), Synset('present.v.02'), Synset('stage.v.01'), Synset('present.v.04'), Synset('present.v.05'), Synset('award.v.01'), Synset('give.v.08'), Synset('deliver.v.01'), Synset('introduce.v.01'), Synset('portray.v.04'), Synset('confront.v.03'), Synset('present.v.12'), Synset('salute.v.06'), Synset('present.a.01'), Synset('present.a.02')]
# 단어별로 어떤 품사를 가지고 있는지 알 수 있음
for synset in synsets :
print(f'Synset Name: {synset.name}')
print(f'POS : {synset.lexname()}')
print(f'Definition: {synset.lemma_names()}')
print('-'*20)Synset Name: <bound method Synset.name of Synset('present.n.01')>
POS : noun.time
Definition: ['present', 'nowadays']
--------------------
Synset Name: <bound method Synset.name of Synset('present.n.02')>
POS : noun.possession
Definition: ['present']
--------------------
Synset Name: <bound method Synset.name of Synset('present.n.03')>
POS : noun.communication
Definition: ['present', 'present_tense']
--------------------(중략)
Synset 객체의 path_similarity() 메서드를 통해 단어의 상호 유사도를 확인 할 수 있다.
import pandas as pd
tree = wn.synset('tree.n.01')
lion = wn.synset('lion.n.01')
tiger = wn.synset('tiger.n.01') # tiger.n.01 -> 사납거나 대담한 사람
cat = wn.synset('cat.n.01')
dog = wn.synset('dog.n.01')
entities = {tree, lion, tiger, cat, dog}
sim = []
entity_names = [entity.name().split('.')[0] for entity in entities]
for entity in entities:
similarity = [ round(entity.path_similarity(compared_entity),2) for compared_entity in entities] # 상호간의 유사도 체크, 실수로 나옴
sim.append(similarity)
sim_df = pd.DataFrame(sim, columns= entity_names, index= entity_names)
sim_df
SentiWordNet 의 주요 기능 확인
WordNet 과 유사한 기능을 갖는 모듈
단어의 감성을 나타내는 '감성지수' 와 객관성을 나타내는 '객관성 지수'를 가지고 있다.
from nltk.corpus import sentiwordnet as swn
senti_synsets = list(swn.senti_synsets('slow'))
print(type(senti_synsets), len(senti_synsets))
print(senti_synsets)
# senti_synsets : 단어에 대해 품사별로 가지고 있는 단어 정의 개수 만큼 알려줌<class 'list'> 11
[SentiSynset('decelerate.v.01'), SentiSynset('slow.v.02'), SentiSynset('slow.v.03'), SentiSynset('slow.a.01'), SentiSynset('slow.a.02'), SentiSynset('dense.s.04'), SentiSynset('slow.a.04'), SentiSynset('boring.s.01'), SentiSynset('dull.s.08'), SentiSynset('slowly.r.01'), SentiSynset('behind.r.03')]
예시 1
father = swn.senti_synset('father.n.01')
print(f'긍정 감성 지수: {father.pos_score()}')
print(f'긍정 감성 지수: {father.neg_score()}')
print(f'객괸성 지수: {father.obj_score()}')
# senti_synset : 객체를 만들어주는 것긍정 감성 지수: 0.0
긍정 감성 지수: 0.0
객괸성 지수: 1.0
예시 2
fabulous= swn.senti_synset('fabulous.a.01')
print(f'긍정 감성 지수: {fabulous.pos_score()}')
print(f'긍정 감성 지수: {fabulous.neg_score()}')
print(f'객괸성 지수: {fabulous.obj_score()}')긍정 감성 지수: 0.875
긍정 감성 지수: 0.125
객괸성 지수: 0.0
SentiWordNet 을 이용한 영화 감상평 감정 분석
분석절차
(1) 문서를 문장 단위로 분해
(2) 문장을 단어 단위로 토큰
(3) 토큰화된 단어의 어근추출 및 품사 태깅
(4) SentiSynset 에서 긍정/ 부정 감정 지수 구하기
(5) (4)번에서 구한 값을 모두 합산하여 특정 임계치 이상일 경우 긍정으로, 그렇지 않으면 부정으로 분류
from nltk.corpus import wordnet as wn
def penn_to_wn(tag):
if tag.startswith('J'):
return wn.ADJ
elif tag.startswith('N'):
return wn.NOUN
elif tag.startswith('R'):
return wn.ADV
elif tag.startswith('V'):
return wn.VERB
# 어근을 추출하여 어근에 해당하는
감성지수 반환 함수 정의
각 단어의 긍정 감성 지수와 부정 감성 지수를 모두 합한 총 감성지수가 0 이상일 경우 긍정감성(1), 그렇지 않을 경우 부정감성(0) 값 변환
from nltk.stem import WordNetLemmatizer # 어근 추출 하기 위한 클래스
from nltk.corpus import sentiwordnet as swn
from nltk import sent_tokenize, word_tokenize, pos_tag # pos_tag : 품사 태깅 함수
def swn_polarity(text):
sentiment = 0.0 # 감정지수 초기화
token_count = 0
lemmarizer = WordNetLemmatizer() # 어근 추출
raw_sentences = sent_tokenize(text)
for raw_sentence in raw_sentences:
# pds_tag(): 품사 분류, 단어와 품사를 갖는 튜플로 반환
tagged_sentence = pos_tag(word_tokenize(raw_sentence))
for word, tag in tagged_sentence:
wn_tag = penn_to_wn(tag)
if wn_tag not in (wn.NOUN, wn.VERB, wn.ADJ, wn.ADV):
# 4개 중 하나가 아니면 감성지수를 받아 낼 수 없는 형태임
continue
lemma = lemmarizer.lemmatize(word, pos = wn_tag) # 단어의 어근을 찾음 (단어만이 아닌 품사정보도 같이 기입)
if not lemma:
continue
synsets = wn.synsets(lemma, pos = wn_tag)
if not synsets:
continue
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
sentiment += (swn_synset.pos_score() - swn_synset.neg_score()) # 긍정 감성 지수 - 부정 감성 지수
token_count +=1
# 총 score 가 0 이상일 경우 긍정(1, 그렇지 않으면 부정(0) 변환
if not token_count:
return 0
if sentiment >= 0:
return 1
return 0
swn_polarity() 함수 구조 파악 테스트 코드
text = review_df['review'][0]
#print(text)
raw_sentences = sent_tokenize(text)
# print(len(raw_sentences))
tagged_sentence = pos_tag(word_tokenize(raw_sentences[0]))
#print(tagged_sentence)
word_list = []
for word, tag in tagged_sentence:
wn_tag = penn_to_wn(tag)
if wn_tag not in (wn.NOUN, wn.VERB, wn.ADJ, wn.ADV):
# 4개 중 하나가 아니면 감성지수를 받아 낼 수 없는 형태임
continue
word_list.append((word,wn_tag))
# print(word_list)[('stuff', 'n'), ('going', 'v'), ('down', 'r'), ('moment', 'n'), ('MJ', 'n'), ('i', 'n'), ('ve', 'n'), ('started', 'v'), ('listening', 'v'), ('music', 'n'), ('watching', 'v'), ('odd', 'a'), ('documentary', 'n'), ('here', 'r'), ('there', 'r'), ('watched', 'v'), ('Wiz', 'n'), ('watched', 'v'), ('Moonwalker', 'n'), ('again', 'r'), ('Maybe', 'r'), ('i', 'v'), ('just', 'r'), ('want', 'v'), ('get', 'v'), ('certain', 'a'), ('insight', 'n'), ('guy', 'n'), ('i', 'v'), ('thought', 'v'), ('was', 'v'), ('really', 'r'), ('cool', 'a'), ('eighties', 'n'), ('just', 'r'), ('maybe', 'r'), ('make', 'v'), ('up', 'r'), ('mind', 'n'), ('is', 'v'), ('guilty', 'a'), ('innocent', 'a'), ('Moonwalker', 'n'), ('is', 'v'), ('part', 'n'), ('biography', 'n'), ('part', 'n'), ('feature', 'n'), ('film', 'n'), ('i', 'v'), ('remember', 'v'), ('going', 'v'), ('see', 'v'), ('cinema', 'n'), ('was', 'v'), ('originally', 'r'), ('released', 'v'), ('has', 'v'), ('subtle', 'v'), ('messages', 'n'), ('MJ', 'n'), ('s', 'v'), ('feeling', 'v'), ('press', 'n'), ('also', 'r'), ('obvious', 'a'), ('message', 'n'), ('drugs', 'n'), ('are', 'v'), ('bad', 'a'), ('m', 'a'), ('kay', 'n'), ('Visually', 'n'), ('impressive', 'a'), ('course', 'n'), ('is', 'v'), ('Michael', 'n'), ('Jackson', 'n'), ('so', 'r'), ('remotely', 'v'), ('MJ', 'n'), ('anyway', 'r'), ('then', 'r'), ('are', 'v'), ('going', 'v'), ('hate', 'v'), ('find', 'v'), ('boring', 'v'), ('call', 'v'), ('MJ', 'n'), ('egotist', 'n'), ('consenting', 'v'), ('making', 'n'), ('movie', 'n'), ('BUT', 'n'), ('MJ', 'n'), ('most', 'a'), ('fans', 'n'), ('say', 'v'), ('made', 'v'), ('fans', 'n'), ('true', 'a'), ('is', 'v'), ('really', 'r'), ('nice', 'a'), ('actual', 'a'), ('feature', 'n'), ('film', 'n'), ('bit', 'n'), ('finally', 'r'), ('starts', 'v'), ('is', 'v'), ('only', 'r'), ('minutes', 'n'), ('so', 'r'), ('excluding', 'v'), ('Smooth', 'n'), ('Criminal', 'n'), ('sequence', 'n'), ('Joe', 'n'), ('Pesci', 'n'), ('is', 'v'), ('convincing', 'v'), ('psychopathic', 'a'), ('powerful', 'a'), ('drug', 'n'), ('lord', 'n'), ('wants', 'v'), ('MJ', 'n'), ('dead', 'a'), ('so', 'r'), ('bad', 'a'), ('is', 'v'), ('MJ', 'n'), ('overheard', 'v'), ('plans', 'n'), ('Nah', 'n'), ('Joe', 'n'), ('Pesci', 'n'), ('s', 'v'), ('character', 'n'), ('ranted', 'v'), ('wanted', 'v'), ('people', 'n'), ('know', 'v'), ('is', 'v'), ('is', 'v'), ('supplying', 'v'), ('drugs', 'n'), ('so', 'r'), ('i', 'a'), ('dunno', 'n'), ('maybe', 'r'), ('just', 'r'), ('hates', 'v'), ('MJ', 'n'), ('s', 'a'), ('music', 'n'), ('Lots', 'n'), ('cool', 'a'), ('things', 'n'), ('like', 'a'), ('MJ', 'n'), ('turning', 'v'), ('car', 'n'), ('robot', 'n'), ('whole', 'a'), ('Speed', 'n'), ('Demon', 'n'), ('sequence', 'n'), ('Also', 'r'), ('director', 'n'), ('have', 'v'), ('had', 'v'), ('patience', 'n'), ('saint', 'n'), ('came', 'v'), ('filming', 'v'), ('kiddy', 'n'), ('Bad', 'n'), ('sequence', 'n'), ('usually', 'r'), ('directors', 'n'), ('hate', 'v'), ('working', 'v'), ('kid', 'n'), ('let', 'v'), ('alone', 'r'), ('whole', 'a'), ('bunch', 'n'), ('performing', 'v'), ('complex', 'a'), ('dance', 'n'), ('scene', 'n'), ('Bottom', 'n'), ('line', 'n'), ('movie', 'n'), ('is', 'v'), ('people', 'n'), ('like', 'v'), ('MJ', 'n'), ('level', 'n'), ('i', 'n'), ('think', 'v'), ('is', 'v'), ('most', 'a'), ('people', 'n'), ('not', 'r'), ('then', 'r'), ('stay', 'v'), ('away', 'r'), ('does', 'v'), ('try', 'v'), ('give', 'v'), ('off', 'r'), ('wholesome', 'a'), ('message', 'n'), ('ironically', 'r'), ('MJ', 'n'), ('s', 'n'), ('bestest', 'a'), ('buddy', 'n'), ('movie', 'n'), ('is', 'v'), ('girl', 'n'), ('Michael', 'n'), ('Jackson', 'n'), ('is', 'v'), ('truly', 'r'), ('most', 'r'), ('talented', 'a'), ('people', 'n'), ('ever', 'r'), ('grace', 'v'), ('planet', 'n'), ('is', 'v'), ('guilty', 'a'), ('Well', 'n'), ('attention', 'n'), ('i', 'n'), ('ve', 'v'), ('gave', 'v'), ('subject', 'n'), ('hmmm', 'v'), ('well', 'r'), ('i', 'a'), ('don', 'v'), ('t', 'n'), ('know', 'v'), ('people', 'n'), ('be', 'v'), ('different', 'a'), ('closed', 'a'), ('doors', 'n'), ('i', 'v'), ('know', 'v'), ('fact', 'n'), ('is', 'v'), ('extremely', 'r'), ('nice', 'a'), ('stupid', 'a'), ('guy', 'n'), ('most', 'r'), ('sickest', 'a'), ('liars', 'n'), ('hope', 'v'), ('is', 'v'), ('not', 'r'), ('latter', 'n')]
리뷰에 대한 감성지수 값을 예측 값으로 계산
review_df['preds'] = review_df['review'].apply(lambda x : swn_polarity(x))
review_df['preds']0 1
1 1
2 0
3 1
4 0
..
24995 1
24996 1
24997 1
24998 0
24999 0
Name: preds, Length: 25000, dtype: int64
예측 정확도 확인
y_target = review_df['sentiment'].values # 영화 감성평의 감성지수 정답
y_hat = review_df['preds'].values # 영화 감상평 감성지수 예측값
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score
print(confusion_matrix(y_target,y_hat))
print(f'정확도: {accuracy_score(y_target, y_hat):.3f}')
print(f'정밀도: {precision_score(y_target,y_hat):.3f}')
print(f'재현율: {recall_score(y_target,y_hat):.3f}')[[ 4186 8314]
[ 1390 11110]]
정확도: 0.612
정밀도: 0.572
재현율: 0.889
(헷갈려서 기입해둠)confusion matrix 보는 법
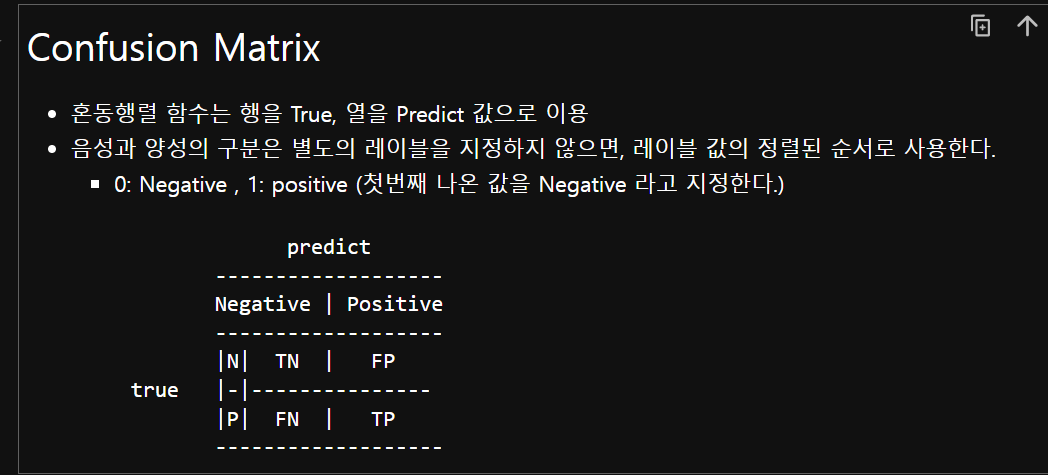
'국비 교육 > 머신러닝, 딥러닝' 카테고리의 다른 글
| [텍스트 마이닝] 한글 텍스트 분석 - 한글 영화 감성분석 (0) | 2024.08.01 |
|---|---|
| [텍스트 마이닝] 문서 군집화 (0) | 2024.08.01 |
| [텍스트 마이닝] 텍스트 분석 -2 [실습] 20 뉴스 그룹 분류 (0) | 2024.08.01 |
| [텍스트 마이닝] 텍스트 분석 -1 (전처리 작업) (0) | 2024.08.01 |

