df = pd.DataFrame([[1,2],[3,4]], index= ['A','B'], columns= ['a','b'])
df새로운 데이터 프레임 생성(인덱스가 A,B , 컬럼명이 a,b 인 1행이 1,2, 2행이 3,4 로 채워진 2행 2열의 데이터 프레임)
데이터프레임 간의 조합
pd.concat()
두 개 이상의 데이터 프레임을 행 또는 열 방향으로 연결한다.
열 방향으로 연결하고자 할 경우 axis = 1 인자를 전달한다.(default: axis = 0)
행 방향으로 연결하고자 할 때는 열 이름이 같아야 하고, 열 방향으로 연결하고자 할 때는 행 이름이 같아야 하다.
df2 = pd.concat([df,df])
df2concat()의 축 기본값이 axis = 0 이기 때문에 열에 방향(아래쪽으로) df가 만들어진다.
df3 = pd.concat([df,df], axis= 1)
df3축 방향을 설정함으로써 행의 방향(옆 쪽으로) df가 만들어진다.
집계함수
모든 집계함수는 axis = 0 을 기본값으로 한다. 일반적인 상황에서 행 방향의 집계는 유의미하지 않다.
df.mean() : 각 행/열에 대한 평균을 산출한다.
df.std() : 각 행/열에 대한 표준편차를 산출한다.
df.min()/df.max() : 각 행/열에 대한 최소/최대값을 산출한다.
[문제] Series, DataFrame 생성 및 연산
- 각 컬럼 값은 Series 객체로 생성
- 앞서 만든 Series 객체를 이용해서 DataFrame 생성
- 각 과목의 합계를 계산한 컬럼 추가
- 각 과목의 평균을 계산한 컬럼 추가
index_list = ['홍길동','임꺽정','전우치','손오공','저팔계','사오정']
sr_major = pd.Series(['컴퓨터공학과','수학과','컴퓨터공학과','수학과','컴퓨터공학과','컴퓨터공학과'], index= index_list)
sr_math = pd.Series([97,88,91,76,88,87], index= index_list)
sr_kor = pd.Series([77,85,90,76,88,77], index= index_list)
sr_eng = pd.Series([90,100,96,91,80,90], index= index_list)각 컬럼의 값을 Series 객체로 생성한다. (나는 하나의 행을 하나의 데이터 프레임으로 만들었다. )
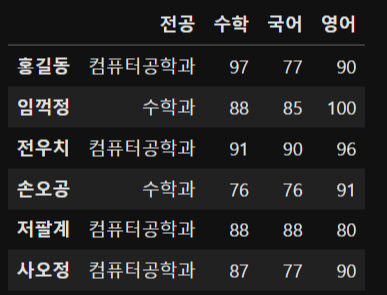
score_df = pd.DataFrame({'전공':sr_major, '수학': sr_math, '국어':sr_kor, '영어':sr_eng})
score_dfSeries 값을 이용하여 데이터 프레임을 생성한다.
# score_df['합계'] = score_df.loc[:,'수학':'영어'].sum(axis=1)
score_df['합계'] = score_df[['수학','국어','영어']].sum(axis=1)
# 복수의 컬럼 목록을 가져오는
# score_df.drop('합계', axis=1,inplace= True)
score_df수학부터 영어까지 슬라이싱 하여 합계를 구한다.
score_df['평균'] = score_df.loc[:,'수학':'영어'].mean(axis=1)
score_df
# 평균값 포맷 적용하기
score_df['평균'] = score_df['평균'].apply(lambda x:f'{x:.2f}')
# x 변수 : 평균 컬럼의 값
score_df 수학부터 영어까지 슬라이싱 하여 평균을 구한다. (람다식을 이용할 수도 있다.)
# 평균값이 object -> float 형변환
score_df['평균'] = score_df['평균'].astype(float)
score_df.info()지금은 예제로 한 문제이기 때문에 평균의 타입을 변경할 필요는 없지만, 한 번 변경해 본다..
import pandas as pd
import numpy as np
data = np.random.randint(0,10,(5,5))
df = pd.DataFrame(data, index = list('ABCDE'), columns= list('abcde'))
df새로운 데이터프레임 생성
결측값 처리
import pandas as pd
import numpy as np
data = np.random.randint(0,10,(5,5))
df = pd.DataFrame(data, index = list('ABCDE'), columns= list('abcde'))
df
# 결측값 설정
df.at['B','c'] = np.nan
df.at['D','e'] = np.nan
df결측값 있는 새로운 데이터프레임 생성
- df.isna(), df.notna()
데이터가 NaN인지 아닌지 검사
checked_nan = df.isna()
print(checked_nan)
# a b c d e
# A False False False False False
# B False False True False False
print(checked_nan.sum()) # 컬럼별 집계
# a 0
# b 0
# c 1
df.dropna()
결측값을 포함한 행 또는 열을 삭제한다. 기본값은 결측값이 존재하는 행을 모두 제거하는 방식이다.
새로운 데이터 프레임을 반환 > 원본의 영향을 받지 않는다.
axis = 1 인수를 설정하면 결측값이 있는 열을 제거할 수 있다
df.dropna()
# a b c d e
# A 8 0 5.0 6 4.0
# C 6 9 0.0 4 4.0
df.dropna(axis= 1)
# a b d
# A 8 0 6
subset 인수를 설정하면 모든 컬럼이 아닌 특정 컬럼의 결측값 데이터만 삭제한다.
df.dropna(subset=['c'])
# 'c' 컬럼의 결측값이 있는 행을 제거한다.
# a b c d e
# A 8 0 5.0 6 4.0
# C 6 9 0.0 4 4.0
- df.fillna()
결측값을 다른 값으로 채운다.
df.fillna(-999)NaN이 -999로 채워진다.
df['c'] = df['c'].fillna(df['c'].mean())
dfc 컬럼에 대해서만 평균값을 집어 넣음
method 인자를 사용하면 열 기준 바로 앞/ 뒤에 있는 값으로 채운다.
method = 'pad' or method = 'ffill' : 앞의 값으로 채운다.
method ='backfill' or method = 'bfill' : 뒤의 값으로 채운다.
# c컬럼에 대해서만 근처값을 집어 넣음
df.fillna(method='pad') # 앞
df.fillna(method='bfill') # 뒤df = pd.DataFrame({'k1':['one','two']*3 +['two'],
'k2': [1,1,2,3,3,4,4]}) #7개 원소 리스트
df새로운 데이터 프레임 생성
데이터 중복 제거
중복 데이터 검사
- df.duplicated()
각 행의 중복 여부를 검사하여 True/False 로 알려준다.
df.duplicated()
# 5 False
# 6 True
# dtype: bool
- df.drop_duplicates()
모든 컬럼에 대해 중복 값을 갖는 행을 제거한다.
df.drop_duplicates()
# 4 one 3
# 5 two 4뒤에 있는 중복된 값이 지워진다.
- df.drop_duplicates(컬럼명 목록)
매개변수로 주어진 컬럼명 목록에 대해 같은 값을 갖는 행을 제거한다.
df['k3'] = np.arange(7)
dfdf.drop_duplicates(['k1','k2'])k1,k2에 대해 중복된 부분을 찾고 k1:k3까지의 중복된 행을 제거 한다.
keep = 'last' 파라매터
drop_duplicates() 는 기본적으로 처음 발견된 값을 유지한다. keep = 'last' 옵션을 지정하면 마지막으로 발견된 값을 유지한다.
df.drop_duplicates(['k1','k2'],keep= 'last')6번째 행이 아닌 5번째 행이 제거된다.
데이터프레임 재구조화
- pd.pivot_table(), df.pivot_table()
피벗 테이블이란
: 기존 데이터를 기반으로 합계나 평균 등의 통계를 산출할 목적으로 새로운 표를 만드는 기능.
df.pivot_table(index = 행방향 컬럼, columns = 열방향 컬럼, values = 집계대상 컬럼, aggfunc = 구할 통계값)
df = pd.DataFrame(np.arange(16).reshape(4,4),
index=list('ABCD'), columns= list('abcd'))
year_df = pd.DataFrame([2019,2020,2019,2020],
index=list('ABCD'), columns= ['year'])
class_df = pd.DataFrame(list('AABB'),
index=list('ABCD'), columns= ['class'])
df = pd.concat([year_df,class_df,df],axis=1)
df새로운 데이터 프레임 작성
pd.pivot_table(df, index= 'year', columns= 'class')
# 연도를 기준으로 재 분류
pd.pivot_table(df,index = ['year','class'])
# 멀티 인덱스도 가능하다중복된 컬럼의 항목은 하나로 합쳐지고 그 값의 평균을 기본 집계 함수로 이용한다.

# pd.pivot_table(df,index='year',values = ['a','b','c','d'])
# 집계값 = 평균값
pd.pivot_table(df,index='year',values = ['a','b','c','d'],
aggfunc=[np.sum, np.mean])
# 집계값 = 합,평균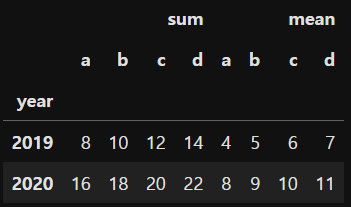
[실습] 피벗 테이블 실습
회사의 연도별, 분기별 판매량과 비용을 만들었다.
sr_year = pd.Series([2020]*4 +[2021]*4+[2022]*4)
sr_quarter = pd.Series(['1Q','2Q','3Q','4Q']*3)
np.random.seed(0)
sr_sales = pd.Series(np.random.randint(500,6000,12))
sr_cost = pd.Series(np.random.randint(100,1200,12))
df = pd.DataFrame({'year':sr_year, 'quarter':sr_quarter, 'sales':sr_sales,'cost':sr_cost})
df
'benefit' 컬럼 추가
df['benefit'] = df['sales'] - df['cost']
df
피봇 테이블을 이용하여 연도별 분기 이익 데이터 확인
# 1.
pd.pivot_table(df, index = 'year', columns='quarter', values = 'benefit')
# 2.
df_pivot = pd.pivot_table(df, index = ['year','quarter'], values = 'benefit')
df_pivot
#3.
df_pivot.index # 튜플의 형태
# 4.
# 연도별 이익에 대한 평균과 합계
pd.pivot_table(df, index = 'year', values = 'benefit', aggfunc=['mean','sum'])# 1. 은 인덱스를 year 로 컬럼명은 연도로 설정하여 이익을 비교하는 피봇테이블이다.
# 2. 는 인덱스를 year과 quarter로 설정하여 이익을 비교하는 피봇테이블이다.
# 4. aggfunc 를 이용하여 sum 함수와 mean 함수를 이용한다.
다중 인덱스
index, columns 에 중첩 배열을 전달해서 다중인덱스를 설정 할 수 있다.
df = pd.DataFrame(np.arange(16).reshape(4,4),
index = [[1,2,3,4],['Java','Python','Java','Python']],
columns=[['1기','1기','2기','2기'],
['오전','오후','오전','오후']])
df
새로운 데이터 프레임 생성
# 1.
df['1기'] # 데이터 프레임 형태
# 2.
df['1기','오후'] # 시리즈 형태
# 3.
df.loc[1,'1기'] # 1행에서 1기에 해당하는# 1. 1기에 오전과 오후가 속해있기 때문에 데이터 프레임 형태이다.
# 2. 1기에 오후로 설정을 했기 때문에 단일값이므로 시리즈 형태로 결과를 반환한다.
# 3. 1행에 해당하며 1기의 속해있는 하나의 값만 결과를 반환한다.
'국비 교육 > 데이터' 카테고리의 다른 글
| [데이터 분석] Pandas 실습 문제 - 1 (시애틀 강수량 데이터 분석) (0) | 2023.11.15 |
|---|---|
| [데이터 분석] Padas - 4 (0) | 2023.11.11 |
| [데이터 분석] Pandas - 2 (0) | 2023.11.11 |
| [데이터 분석] Pandas - 1 (0) | 2023.11.11 |


